Trie/字典树/前缀树
Trie树是一种针对字符进行特殊优化的数据结构,也许这也是它被称为字典树的缘故。 其优势在于:
- 节省存储空间: 假设存储这样的键值对:
1 2 3
apple:1 app:2 appl:3
- 如果使用哈希表存储,则键值对会被存储在底层
table数组中,意味着它真的创建了appleappappl字符串,占用了12个单位的空间 - 如果使用Trie树来存储,其底层并不会重复存储公共前缀,所以仅需
"apple"这5个单位的内存空间 - 因此当键非常多并且非常长,特别是含有大量公共前缀的时候,使用Trie树就能节省大量空间
- 如果使用哈希表存储,则键值对会被存储在底层
- 方便处理前缀操作
- 支持通配符匹配(“.”)
- 可按照字典序遍历键
实现
前文中提到,多叉树的节点实现代码如下:
1
2
3
4
class TreeNode:
def __init__(self):
self.val = None
self.children = []
而Trie树的实现代码则是这样:
1
2
3
4
class TrieNode:
def __init__(self):
self.val = None
self.children = [] * 256
需要注意的是:与之前多叉树不同,TrieNode中children的索引是有意义的,代表键中的一个字符:
- 比如
children[97]如果非空,则说明存储了字符'a',因为字符a的ASCII码为97 - 这里我们只考虑处理ASCII,因此将
children数组大小设置为256,其可以灵活变化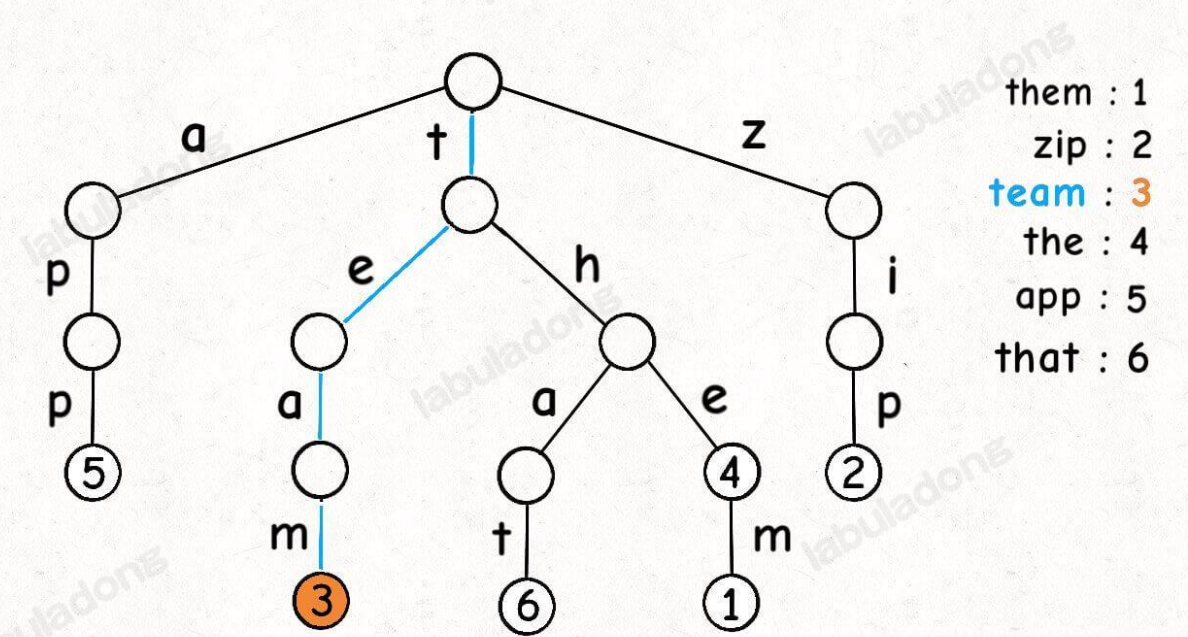 这里要特别注意,
这里要特别注意,TrieNode节点本身只存储val字段,并没有一个字段来存储字符,字符是通过子节点在父节点的children数组中的索引确定的。 形象理解就是,Trie树用「树枝」存储字符串(键),用「节点」存储字符串(键)对应的数据(值)。所以我在图中把字符标在树枝,键对应的值val标在节点上
This post is licensed under CC BY 4.0 by the author.